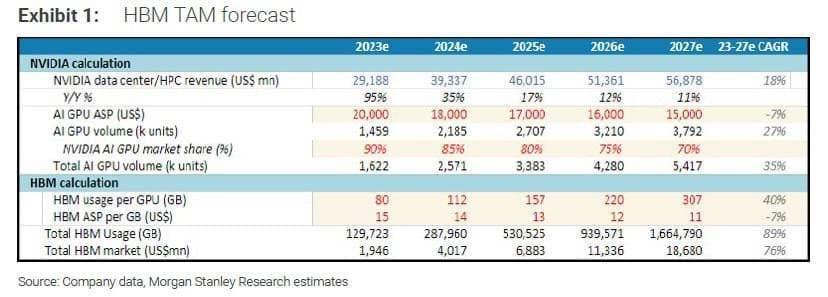
HBM 향후 판매량 전망에서 단순 GPU 출하량 갯수뿐만 아니라 GPU 당 탑재량도 같이 봐야 하는 게 바로 이 때문임. 그래서 첨부한 모건스탠리 리포트에서도 27년 GPU 당 HBM 용량(HBM usage per GPU)을 307GB로 계산했던 것임. 뿐만 아니라 대역폭도 HBM2E(A100)에서 HBM4(차차세대 GPU)로 가면서 몇 배씩 증가한다는 점을 감안하면 GPU의 HBM 전체 성능이 세대가 업그레이드 되면서 수십배 상승한다고 보면 됨. 예컨대 HBM2에서 3으로 가면서 대역폭이 3.2배 상승(256GB/sec->819GB/sec)했다는 점을 감안하면 HBM4의 대역폭 역시 3 대비 최소 3배 이상은 될 것이고, 용량 증가까지 감안하면 엔비디아 차차세대 GPU의 HBM 종합 성능은 H100 대비 거의 20배 가까이 상승할 것으로 전망함. 정말로 어마어마한 성능의 괴물 칩이 출시되는 것임.
결론은 AI 컴퓨팅에는 앞으로 Near Memory인 HBM부터 SCM인 CXL까지 디램이 그냥 개같이 존나 많이 들어갈 수밖에 없다 이상임.